Machine Learning Operations
MLOps, o Machine Learning Operations, es una práctica que se centra en la integración y la gestión de sistemas de machine learning en un entorno de producción de manera eficiente y efectiva. A continuación, voy a registrar un modelo en MLflow y posteriormente voy a encapsularlo y desplegarlo en Docker.
El modelo de predicción es el siguiente: https://github.com/Guill3TR/Datathon_Project/blob/main/4_train_test_deploy.ipynb
1- Inicio MLflow mediante el siguiente comando en el puerto 5000.


2- Importo la librería mlflow, defino la URL del servidor de MLflow, en este caso, el puerto local 5000, y configuro la URI de seguimiento de Mlflow. Después, me conecto al experimento «DATATHON».
Cuando se llama a mlflow.sklearn.autolog(), MLflow automáticamente comienza a rastrear cierta información sobre el modelo Scikit-learn que está siendo entrenado. Esto incluye parámetros de entrada, métricas de rendimiento y otros metadatos relevantes para el modelo.
En términos prácticos, esto significa que no es necesario registrar manualmente cada parámetro del modelo o métrica de rendimiento que desee supervisar. La función autolog() se encarga de esto automáticamente, lo que simplifica enormemente el proceso de seguimiento y registro del modelo.
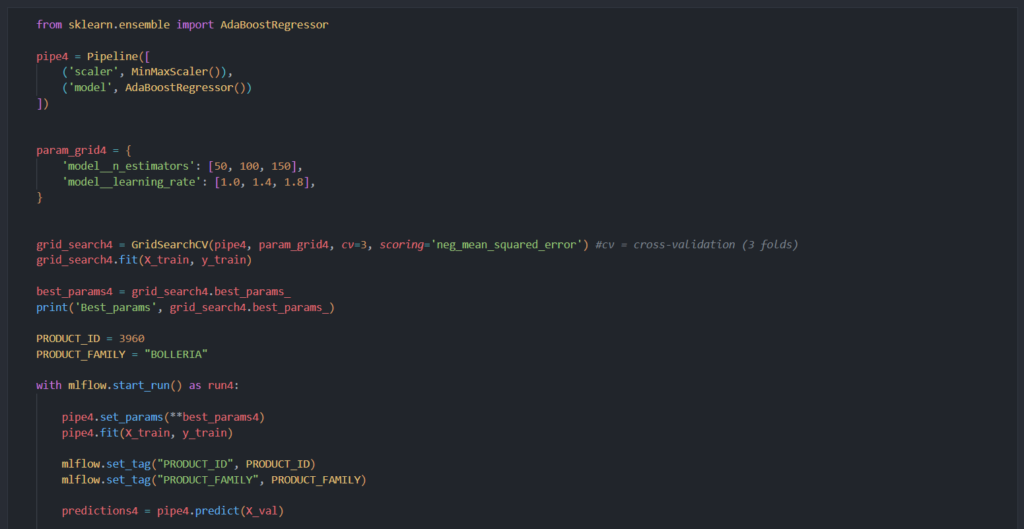
3- Creo un pipeline para escalar y entrenar el modelo con el ensamblador AdaBoostRegressor. Además, modifico los hiperparámetros del modelo y hago cros-validación. Me quedo con la mejor combinación e inicio un nuevo run. Con autolog() se registran automáticamente ciertos parámetros y métricas relevantes. Manualmente registro 3 métricas fundamentales.

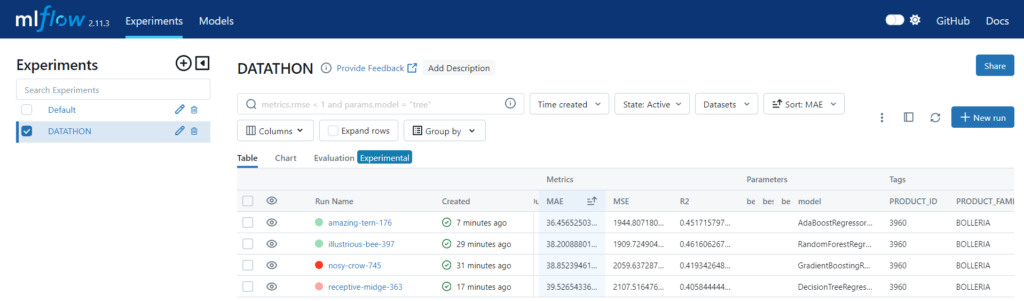
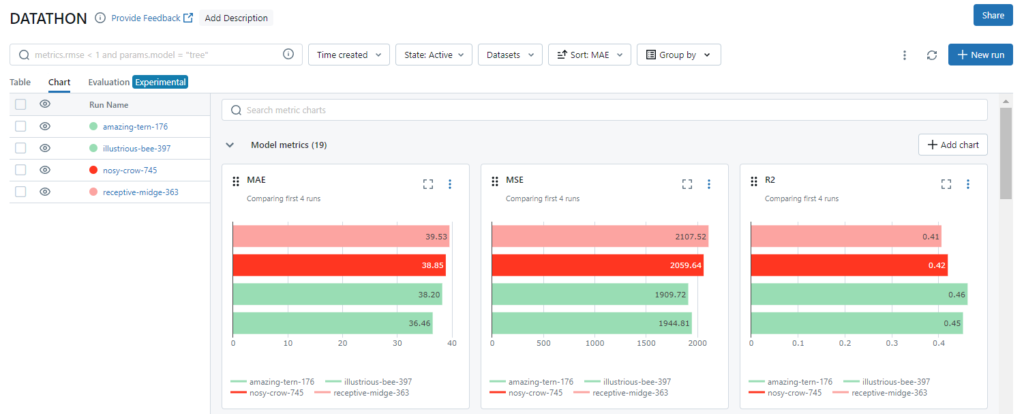
4- Defino la ruta donde se ubica el modelo, y posteriormente lo registro. Cada vez que se registra se crea una nueva versión. También le asigno una etiqueta al modelo.
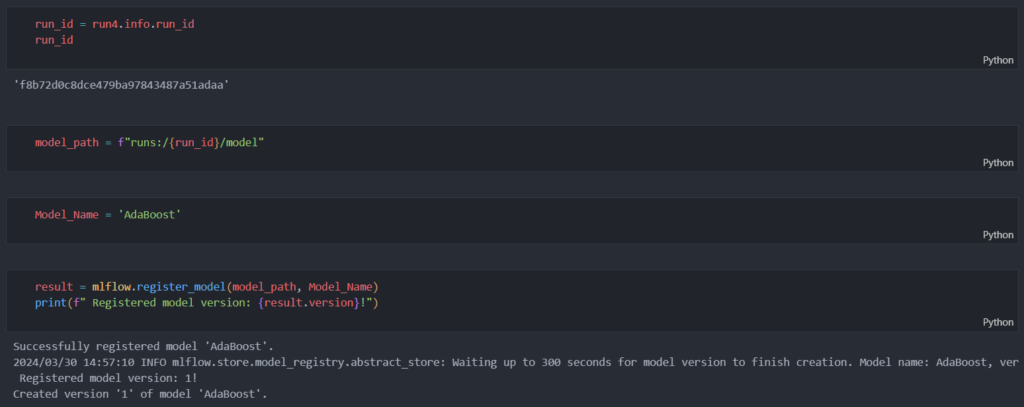

5- Utilizo Docker para encapsular y ejecutar MLflow dentro de un contenedor. Docker proporciona portabilidad y reproducibilidad, ya que el contenedor Docker contiene todas las configuraciones y dependencias necesarias.
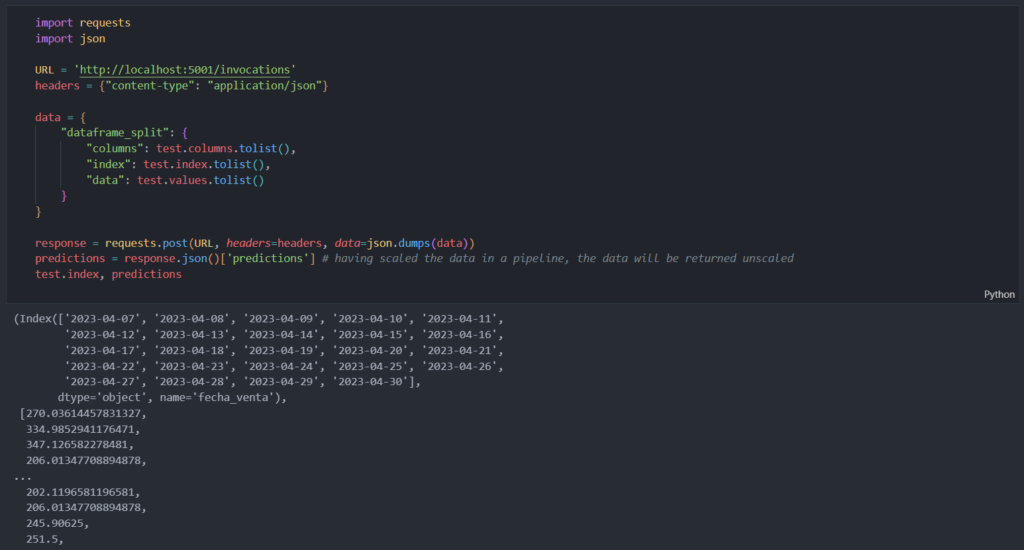
6- Preparo los datos que voy a utilizar para predecir los resultados, creo la cabecera y el cuerpo, y por último, transformo los datos de python a JSON. Por último, genero la solicitud y muestro los resultados.